

Una nuova tecnologia firmata Google Research sta facendo parlare parecchio nel mondo tech, e il motivo è piuttosto semplice da capire. Si chiama TurboQuant ed è un algoritmo pensato per tagliare in modo drastico il consumo di memoria quando i modelli di intelligenza artificiale sono in funzione. Già, perché far girare questi sistemi costa un patrimonio in termini di risorse hardware, e qualsiasi miglioramento su quel fronte è oro colato per chi lavora nel settore. La cosa curiosa è che l’annuncio ha scatenato anche una certa ironia online: in tanti hanno tirato in ballo la serie tv Silicon Valley, quella dove una startup inventava un algoritmo di compressione talmente potente da sembrare fantascienza. Il parallelo regge fino a un certo punto, ma fa capire quanto la promessa di Google TurboQuant suoni ambiziosa.
Come funziona e perché potrebbe cambiare le carte in tavola
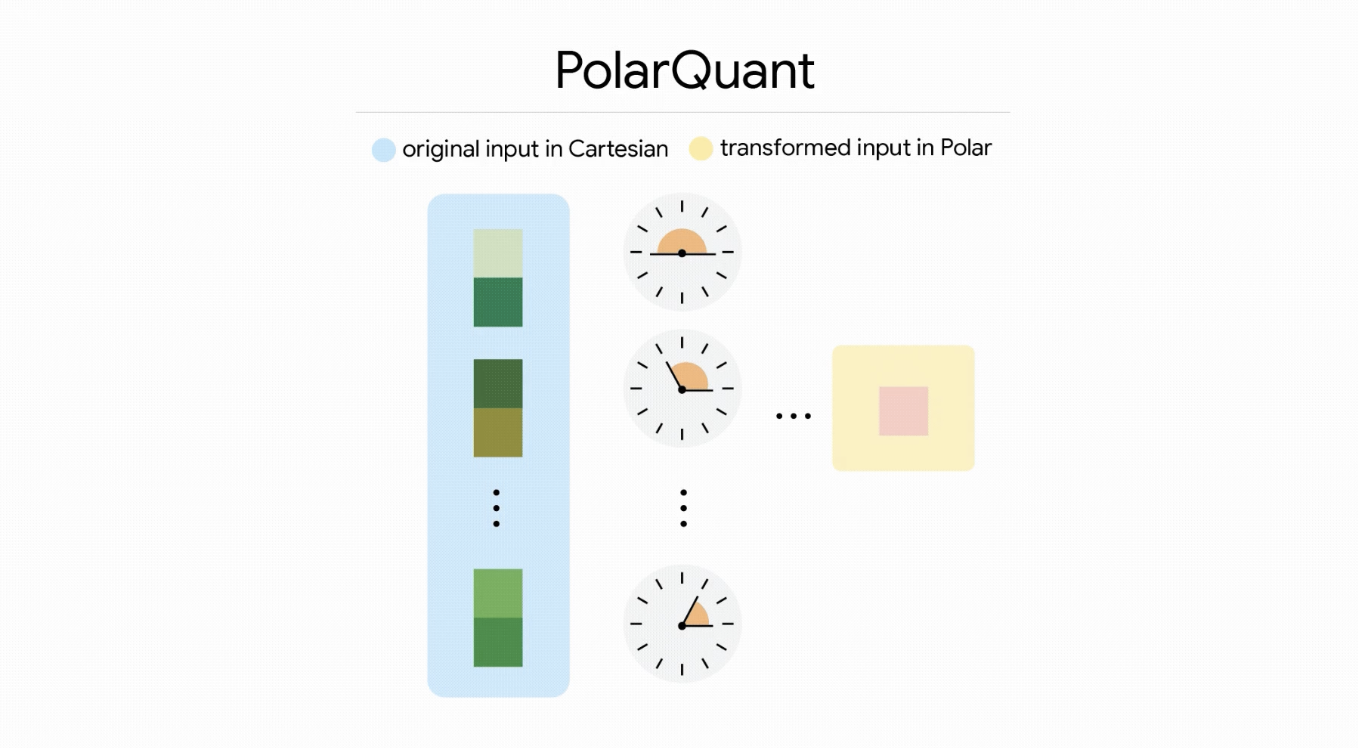
Il cuore del progetto riguarda un problema molto concreto: la cosiddetta KV cache, cioè la memoria di lavoro che i modelli utilizzano durante la fase di inferenza, quella in cui generano effettivamente le risposte. Attraverso tecniche avanzate di quantizzazione vettoriale, TurboQuant riesce a comprimere questa memoria in modo significativo senza sacrificare la qualità dei risultati. Tradotto in parole semplici: i modelli riescono a gestire più informazioni occupando molto meno spazio.
I numeri parlano chiaro, almeno sulla carta. Secondo i ricercatori, la riduzione della memoria potrebbe arrivare fino a sei volte rispetto ai metodi tradizionali. Questo significherebbe costi operativi decisamente più bassi e una maggiore accessibilità per chi non dispone di infrastrutture hardware mastodontiche. Il progetto comprende anche due tecniche complementari, chiamate PolarQuant e QJL, che si occupano rispettivamente della quantizzazione e dell’ottimizzazione del modello. I dettagli tecnici completi verranno presentati alla conferenza ICLR 2026, uno degli eventi più importanti nel campo del machine learning.
Il confronto con DeepSeek è molto interessante
Qualcuno ha provato ad accostare TurboQuant ai progressi ottenuti da DeepSeek, che ha fatto notizia per aver migliorato l’efficienza dei modelli riducendo i costi di addestramento. Il confronto però zoppica parecchio: Google TurboQuant interviene sulla fase di inferenza, mentre l’addestramento resta comunque un processo che richiede enormi quantità di memoria e potenza di calcolo. Sono due problemi diversi, e risolverne uno non elimina automaticamente l’altro.
