

Nel campo dell’intelligenza artificiale multimodale, uno dei nodi più difficili da sciogliere resta l’equilibrio tra comprensione visiva e generazione di immagini. I sistemi attuali, nella maggior parte dei casi, sono costretti a privilegiare una delle due dimensioni, accettando compromessi strutturali. È su questo limite che si concentra Manzano, il nuovo modello descritto in uno studio firmato da un ampio gruppo di ricercatori di Apple.
Il limite strutturale dei modelli multimodali

Secondo lo studio, la difficoltà nasce dalla tokenizzazione visiva, ovvero dal modo in cui un’immagine viene trasformata in informazioni elaborabili dal modello. I sistemi autoregressivi, usati per generare immagini passo dopo passo, lavorano meglio con token discreti. La comprensione, invece, beneficia di rappresentazioni continue, più ricche sul piano semantico.
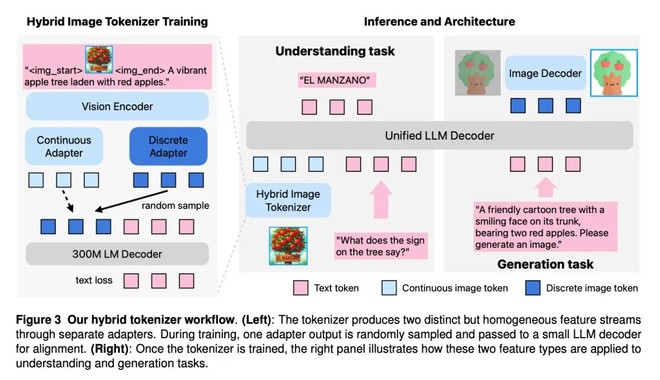
Per aggirare il problema, molte architetture adottano due rappresentazioni separate: una continua per l’understanding e una quantizzata per la generazione. Questa soluzione, però, introduce un conflitto interno. Il modello linguistico deve gestire token molto diversi tra loro, legati sia a concetti astratti sia a dettagli spaziali di basso livello, con un impatto negativo su efficienza e qualità complessiva. Altri approcci, come le architetture a percorsi separati o l’uso di decoder esterni per la generazione, migliorano singoli aspetti ma rinunciano a una reale integrazione.
L’architettura alla base di Manzano
Manzano nasce per superare questi compromessi. L’idea chiave è una separazione funzionale più netta: il modello linguistico autoregressivo si occupa della previsione semantica, mentre la resa finale dei pixel è affidata a un decoder di diffusione.
Il sistema si fonda su tre elementi: un tokenizer visivo ibrido, capace di produrre sia rappresentazioni continue sia token discreti; un decoder LLM che accetta testo ed embedding visivi continui e predice token da un vocabolario condiviso; un decoder di immagini che ricostruisce i pixel. In questo modo, nessuna singola rappresentazione viene forzata a soddisfare esigenze incompatibili.
Prestazioni e flessibilità operativa
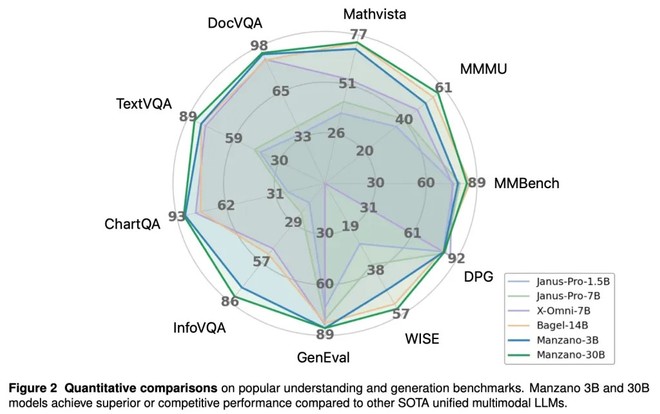
Nei test, Manzano gestisce anche prompt controintuitivi o fisicamente improbabili, mantenendo coerenza semantica e visiva. Le valutazioni su modelli che vanno da 300 milioni a 30 miliardi di parametri mostrano miglioramenti costanti con la scala, con le versioni più grandi competitive rispetto allo stato dell’arte sia nella comprensione sia nella generazione.
Il modello si distingue anche nelle attività di editing e trasformazione delle immagini, come modifiche guidate da istruzioni testuali, trasferimento di stile, inpainting, outpainting e stima della profondità. Un segnale che suggerisce un approccio più flessibile rispetto ai sistemi focalizzati esclusivamente sul text-to-image.
